








この記事の内容
GPU(RTX30606Ti)を用いた計算の高速化
久しぶりの真面目な記事です。
本記事ではGPUによる機械学習の計算の高速化の試みについて記しておきたいと思います。
結論としては、RTX3060Ti搭載のPCでは、これまで使用していたノートPC(Tensorflow対応のGPU非搭載)と比較してLSTMモデルの実行速度が約15倍と非常に速くなりました。(ちなみに精度に大きな変化は見られませんでした)
例えるなら新幹線(300km/h)vs原付(20km/h)ですね。
備忘録としての記事ですので、間違いがあるかもしれませんが、ご了承ください。
GPUのある/なしが実行速度に与える影響を考えるにあたり、私は以下の2つ種類の検証を行うことができました。
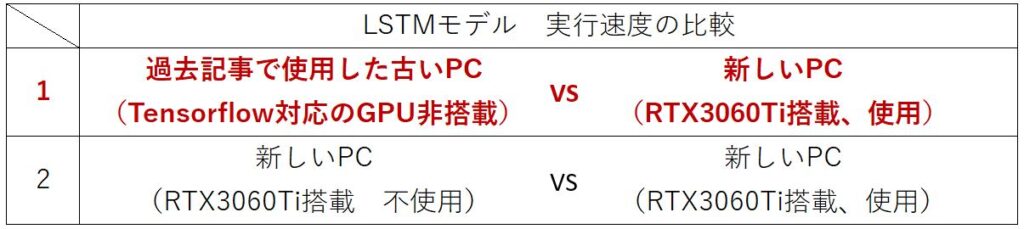
本記事では、過去記事の内容を踏まえつつ、1の比較について記します。
これまでの機械学習に関する取組み
以前から機械学習の勉強は細々と続けており、過去には記事にしたこともあります。
このあたり↓

ちょうど1年前くらいの記事ですね。
これらの記事でも触れていますが、機械学習では計算量が膨大であり、素早く実行するためには、ハード面の整備も重要かと思います。先日購入したRTX3060Ti搭載のPCに、TensorFlowの環境を構築したことで、ようやく実際に機械学習を行えるようになりました。
高速化に向けての取組み
今回の試みでは過去記事と同じプログラムを使用し、新しいPCと古いPCの計算速度を比較します。
つまり今回もTOPIX連動型上場投資信託の価格予測を行うということですね。
ちなみに前回と同じプログラムを使用しているため、価格予測は必ず失敗します。(夢がないですが💦)
今回注目するのは実行速度です。機械学習では沢山のパラメータを適切な値に調整しモデルが出力する答えの精度を高めるという作業を行います。(私の記憶が正しければ…)。ここで問題となるのは、パラメータの値の調整に沢山の時間が必要であることです。この作業では、値を調整する毎にプログラムを実行し、精度が低ければ他の値に変えて再度プログラム実行…と地道に良い値を探索していきます。
したがって、
実行速度が速い
→短期間で何度もプログラムを実行できる
→短期間に沢山のパラメータを調整できる
→良いモデルを短期間で構築できる
といえます。つまり実行速度が速ければ速いほど、高精度なモデルを素早く構築できる可能性が高いということです。
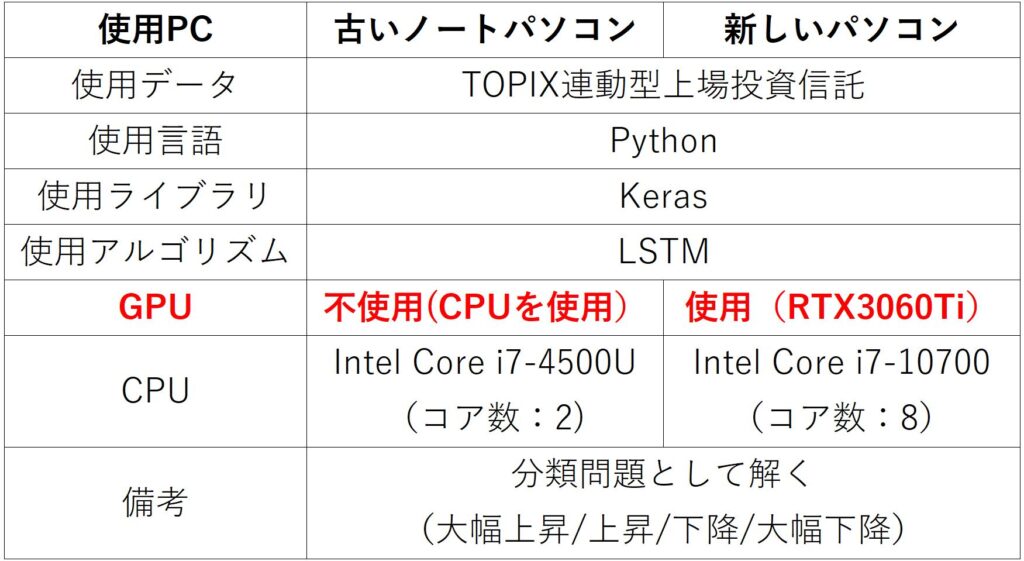
検討条件(旧PC vs 新PC)
条件は前回と同じですが一応簡単に記しておきます。(前回同様Kerasを用いてLSTMモデルを構築)
構築したモデル:
1 全結合層・ユニット数:50
2 LSTM層・ユニット数:50
3 全結合層・ユニット数:4
その他パラメータ
学習回数:100、バッチサイズ:32
原則として過去記事で使用したモデルを可能な限り踏襲することとしました。したがって主要なパラメータ(学習回数、層数、1層あたりのユニット数、バッチサイズなど)は過去記事と同じです。
一方で活性化関数(ReLU関数からSigmoid関数へ)の種類などは変更しています。これはLSTM層においてGPUを使って実行するためには一部パラメータを所定の値にする必要があるためです。所定以外のパラメータを使用した場合、プログラム自体は実行できますが、GPUの性能を完全に引き出すことができず、高速化できないようです。ちなみ詳しい情報はKeras公式HPに記載されています。
Keras公式HP活性化関数にSigmoid関数を使うと勾配消失が生じる可能性が高まるため、なるべく使いたくないのだが、高速化のためにはやむなしか…(独り言)
検討結果
精度→改善なし
今回の試みの趣旨は「前回と比較してどれだけ計算が高速化されたかの検証」ですが、一応プログラム実行結果を示しておきます。今回も過去記事と同様、予測の正確性を評価する指標として精度に着目しました。価格の推移を4択問題(大幅上昇/上昇/下降/大幅下降)として扱っており、全問正解で100%、全て外すと0%となります。構築したモデルにおける学習回数と精度の推移を下に示します(図1)。
まず新しいパソコンでGPU(RTX3060Ti)を使用して実行した場合の結果を図1に示します。
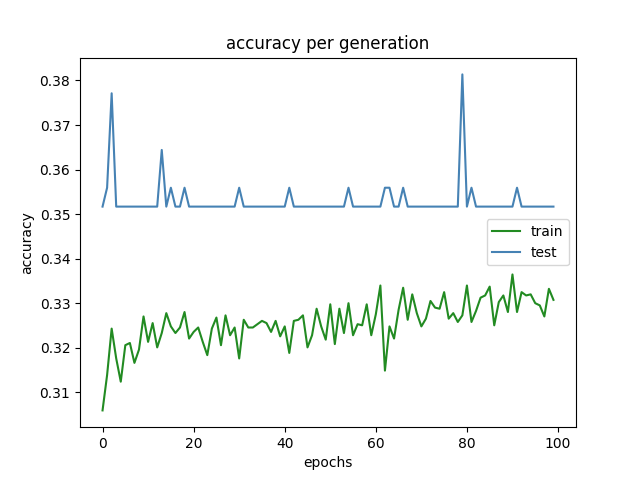
図1 精度の推移(学習回数=100回、GPU使用)
簡単に図1の説明をしておきますと、縦軸は精度、横軸は学習回数です。また緑色の線は教師データに対する精度、青色の線はテストデータに対する精度です。テストデータに対する精度は学習が100回終了した時点で35.2%(ちなみに前回も35.2%でした)。一見すると、四択問題をデタラメに解いた時(=25%)よりは高い精度ですが、やはり過去記事と同様、教師データの学習が十分に進んでいないため、予想としては使えません。
次に古いパソコンでGPUを使用せずに実行した場合はこんな感じでした(図2)。
.png)
図2 精度の推移(学習回数=100回、GPU不使用)
このように精度に関しては、どちらの場合でも大して差がないことが分かります。
計算速度→GPU使用により高速化に成功!!
計算終了に要した時間を下に示します。
古いノートPC(Tensorflow対応のGPU非搭載):440秒
新しいPC(RTX3060Ti使用):30秒
RTX3060Ti搭載の新しいPCでは、古いPCと比較して約15分の1の時間で計算を終えることができました。これはかなり大きいですね。
これまで2週間かかっていた計算が1日以内に完了させられるということですね。
もっと大げさに言えば、古いPCで1年かかる計算も新しいPCなら1か月以内で完了するということになります。
一方で今回の試みで新たな課題も見つかりました。それはGPUを使用した処理ではプログラム実行開始までに非常に時間がかかるということです。実行を命じてから実際に動き始めるまでに15分くらいかかりました。おそらく私の書いたプログラムがポンコツなだけで、今後改善していくことは可能かと思われます。もし仕様だったら諦めます。
とはいえ、実際のモデル探索では複数種類のパラメータを調整することが一般的で、計算量が膨大になると考えられます。(4種類のパラメータ各々について10通りの候補を試すだけでも10000通り…)そのためプログラムが動き始めれば、超高速で処理できるGPUが有利であることには変わりないと思われます。実際、モデル探索する際には数日間計算させ続けたりしますし、最初の15分くらいすぐに取り返せますね(笑)
まとめ
RTX3060Ti搭載の新しいパソコンでは古いパソコンと比べてLSTMの実行速度が15倍となった。
しかしながら実行を命じてから実行開始まで15分くらい要するため、今後改善する必要がある。
また予測精度については新しいPCと古いPCで大きな差は見られなかった。


コメント