







はじめに
お久しぶりです。
これまでは旅行や釣りの話などを書き連ねてきましたが、今回は趣向を変えて真面目(?)な話です。そこまで大した話ではないのですが、少し前に始めた機械学習の勉強について、反省&改善の際に参考とするべく、記すことにしました。一言で記すと機械学習で実験的に株価(投資信託の価格)の予測を試みましたが、プログラムが未熟で実用に耐えるものはできなかったというのが要旨です。また本記事にソースコードは載せていません。参考にされる際には自己責任でお願いします。
目標:「機械学習による株価 / 投資信託の価格の予測」
巷で機械学習が流行っている事や日々の業務においてもプログラミングをする機会が少しずつ増えてきていることから、業務以外のプライベートの時間でも機械学習の勉強をしておこうと思い立ちました。そこで当面の目標として「機械学習による株価の予測」を試みることとしました。本目標を設定した理由ですが、一見すると単調になりがちな勉強も株価の予測というある意味不純な(?)動機があれば楽しくできそうと考えたからです。(極論を言えば)株価の予測ができなくてもプログラムに対する理解が少しでも進めば良いかなという気持ちでした。
概要 / 現段階での成果
今回の勉強ではKeras(ライブラリの一種)の公式ホームページを中心に勉強を進めました。当初は株価予測を行っているホームページを参考にしようとも考えたのですが、株価予測の成功例が公開されているはずもなく、悪戦苦闘しながら自力でモデルを構築する(=プログラムを書く)ことになりました.現段階では「Kerasを用いて少し先の株価の増減を予測」という動作をするプログラムを作成しました。以下に流れを記しておきます。
準備
使用言語はPython
目指したのは一から機械学習のアルゴリズムを構築するのではなく、機械学習のライブラリを用いて株価を予測することです。プログラムを全く書かずに機械学習のモデルを構築する方法もあるかもしれませんが、私はプログラミングに詳しくなりたいという動機から、ライブラリを利用しつつ自分でプログラムを書き機械学習のモデルを構築することにしました。プログラミング言語の選択ですが以下の理由からPythonを選択しました。
- これまでに多少触る機会があった
- 先輩が使っていた
- 機械学習に適しているとされている言語らしい
- ライブラリが充実しているようだ
- 使用人口が多く、情報が得やすいと考えられる
Pythonを使用して実際に機械学習をやってみよう!と思ったものの環境の構築で苦労しました。実際に行った作業は以下の通り。
- 自分のパソコンにPythonの環境を構築
- 必要なライブラリ(Kerasほかグラフ作成の為のライブラリなど)をインストール
- 実際にプログラムを書く
- プログラムを実行する
- エラーの修正
- 4,5の繰り返し
一通り使えるライブラリが含まれたAnacondaを最初にインストールしておくと、後から諸々のライブラリをインストールする必要がなく、楽なようです(Pythonを勉強した経験のある先輩が教えてくれました。)
使用するアルゴリズムは”LSTM”
一口に機械学習と言っても様々な手法がありますが、今回はLSTMと呼ばれる手法を利用しました。LSTMは時系列データの予測に利用可能であり今回の目的に適合すると考えました。
予測にあたっての工夫「上昇 / 下降を4つに分類」
初は株価の値そのものを予測しようと考えましたが、予測値が実際の値とどれだけ離れているか評価するのは難しい面倒くさいと感じました。そのため今回の試みでは「大幅に上昇」「上昇」「下降」「大幅に下降」の4種類のラベルを用意し4択問題として予測を行いました。(過去のデータをもとに未来のある1日の株価が過去と比較して「大幅に上昇」「上昇」「下降」「大幅に下降」のどれになるのかを予測)
検討対象は”TOPIX連動型上場投資信託”
当初は1つの企業に絞ることも考えましたが、投資信託の方が全体的な傾向を掴みやすく、予測しやすいのではないかと考えました。教師データは2001年から2017年の終値のデータ、テストデータは2018年の終値のデータとしました。また後述のモデルにデータを入力する際には、これらの終値のデータを1000で割ったデータを使用しました。
モデル構築
ライブラリは”Keras”
機械学習を行うためのライブラリは様々な種類がありますが私が使用したのはKerasというライブラリです.その理由は機械学習初心者にとって易しそうだったからです.他にもTensorFlowという有名なライブラリもありますが,こちらは少し難しそうな雰囲気でしたのでKerasにしました.
Kerasを用いた予測モデル構築
LSTMでは過去の時系列データから未来のデータを予想することができるようです.今回構築したモデルは「ある10日間を対象に1日目から7日目までの終値の推移を学習し、10日目の終値が9日目の終値と比較してどうなるか(大幅に上昇、上昇、下降、大幅に下降)を予測」するモデルです。モデルの具体的な構造を以下に記します。
1層目 全結合層、ユニット数:50
2層目 LSTM層、ユニット数:50
3層目 全結合層、ユニット数:4
とりあえず層数は3層、学習回数は100回で様子を見ます。またバッチサイズは32としました。あくまで今回は実験的な試みであるため、学習回数・関数の選択・層数、ユニット数を含む全てのパラメータに深い意味はなく、大雑把に設定しました。
予測結果
今回は予測の正確性を評価する指標として精度に着目しました。先述のように今回は価格の推移を4択問題として扱っていますので、全問正解で100%、全て外すと0%となります。構築したモデルにおける学習回数と精度の推移を下に示します(図1)。
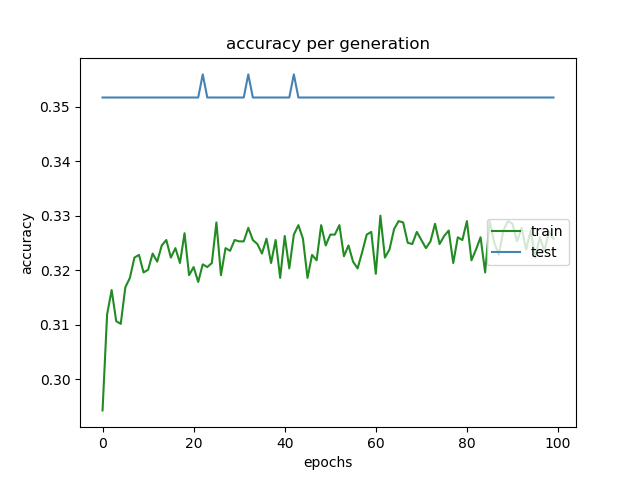
図1において、縦軸は精度、横軸は学習回数、緑色の折れ線は教師データに対する精度、青色の折れ線はテストデータに対する精度です。図1よりテストデータに対する精度が教師データに対する精度よりも高い結果となり、今回構築したモデルが機能していないことが分かります。以下に具体的な考察を記します。
まず教師データに対する精度に注目します。図1に示すように、学習が進行した際にも教師データに対する精度はそれほど上昇しませんでした。またその精度は100回目の学習が完了した時点で33%以下と微妙な値です。
次にテストデータに対する精度に着目します。図1より、こちらも大きな変動は見られないことが分かります。ちなみに学習回数が100回に到達した時のテストデータに対する精度は35.2%でした。この精度は4択問題をデタラメに解いたときの確率( = 25 % )よりも高い精度です。しかし、先述のように教師データに対する精度が33%前後と低いことを踏まえると、この結果はモデルが教師データの特徴を充分に学習した上で出力したものではなく、偶然高い精度となったものであるといえそうです。
以上より今回構築したモデルは実用的ではないと考えています。
今後の課題
予測結果の評価方法
本検討では予測結果の正確性を図る指標として精度に着目しましたが、損失関数の大きさなど他の指標に着目すると、また異なる知見が得られるかもしれません。
パラメータ調整
今回は実験的に投資信託の価格の予測を行いました。あまり良い結果は出ませんでしたが、様々なパラメータおよび学習回数を適切な値とすることで、精度が向上する可能性はありそうです。時間があれば色々と試してみたいと思います。
ハード面の整備
今回は学習回数を100回としましたが学習終了に約5分かかりました。今後本気でモデルを構築するのであれば、計算量の増大は不可避であると考えられます。高性能なパソコンが必要になりそうです。
追記:GPU搭載のパソコンを用いて計算速度を向上させました↓

参考文献
今回の試みでは投資信託の価格の予測にKeras、学習の進行状況を把握するグラフの作成にMatplotlibを使用しました。
Keras:https://keras.io/ja/
Matpoltlib:https://matplotlib.org/index.html


コメント